머신러닝을 시작하기 전에 어떤 도구를 쓸 것인가 부터 정리해야 한다. 통계를 할때는 SPSS, STATA, SAS, R 과 같은 프로그램을 사용하였지만, 머신러닝은 주로 python 프로그램을 이용한다. 따라서 python 프로그램 사용에 대한 기본기는 갖추고 있어야 한다. 물론 최근에는 AI 도구들이 있어, 바이브코딩으로도 쉽게 코드를 작성하고, 실행할 수 있지만 적어도 어떻게 코드를 실행을 하는지는 알아야하고, 코드 실행에 필요한 사항도 알아야 데이터를 맞게 준비할 수 있어 기본적인 사항은 알아야 한다.
1. 머신러닝 도구
머신러닝의 사실상 표준 언어는 Python이다. R도 사용되기는 하지만, 수많은 라이브러리들이나 머신러닝 커뮤니티, 실무자들 모두 Python을 주로 사용하면서 자연스럽게 Python이 머신러닝의 표준이 되었다.
머신러닝 도구는 3단 구조이다. 이걸 이해하면 모든 도구의 위치가 명확해진다.
[3단계] 전문 ML/DL 라이브러리
scikit-learn · TensorFlow · PyTorch · XGBoost ...
↑ 이들은 모두 아래 도구를 활용한다
[2단계] 데이터·연산 기초 라이브러리
NumPy · Pandas · Matplotlib
↑ 이들은 모두 아래 언어로 작성된다
[1단계] 프로그래밍 언어
Python
모델 하나를 학습시킨다고 하면, Python으로 프로그램을 작성하고, NumPy로 수치 연산을 하고, Pandas로 데이터를 다루고, scikit-learn으로 알고리즘을 호출한다.
2. 데이터·연산 기초 라이브러리
이 단계는 모든 ML 코드가 의존하는 기반이다. 직접 호출하지 않아도 ML 라이브러리들이 내부에서 사용한다.
2-1. NumPy — 수치 계산의 표준
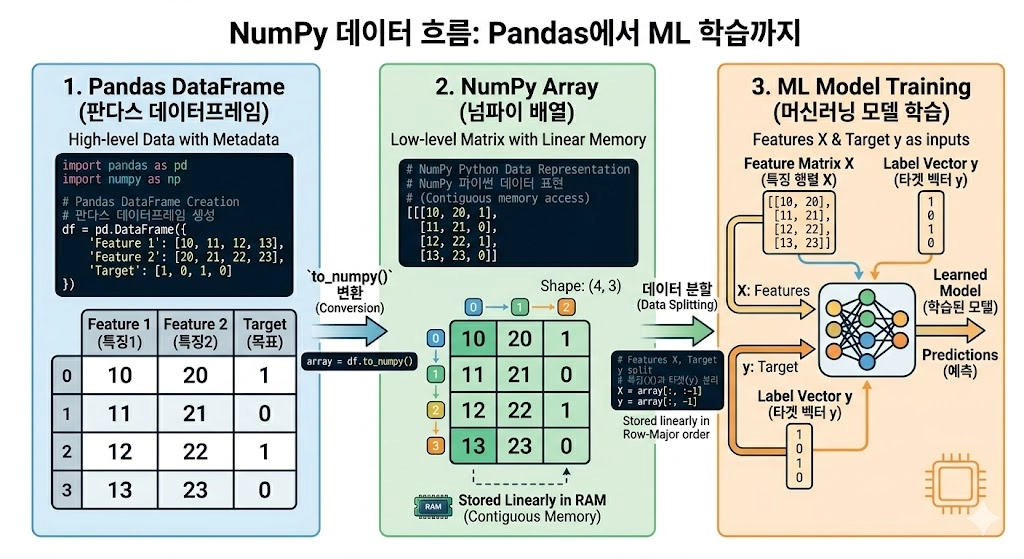
NumPy는 다차원 배열과 수치 연산을 제공한다. 머신러닝의 모든 데이터는 결국 숫자의 행렬이고, 그 행렬을 효율적으로 다루는 도구가 NumPy이다.
핵심 — ndarray라는 다차원 배열 객체. Python의 기본 list보다 100-1000배 빠르다 (C로 구현된 연속 메모리 배열).
import numpy as np
# 벡터 (1차원)
a = np.array([1, 2, 3, 4, 5])
b = a * 2 # 벡터화: 모든 원소에 동시 적용
# 결과: [2, 4, 6, 8, 10]
# 행렬 (2차원)
X = np.array([[1, 2], [3, 4]])
y = np.array([5, 6])
result = X @ y # 행렬-벡터 곱ML에서의 위치 : scikit-learn, TensorFlow, PyTorch 모두 내부적으로 NumPy 배열을 표준 데이터 형식으로 사용한다. NumPy는 ML 생태계의 공용어 이다.
2-2. Pandas — 데이터 핸들링의 표준
Pandas는 표 형식 데이터를 다루는 라이브러리이다. R의 data.frame을 Python으로 가져온 것과 비슷하다.
DataFrame 이라는 행과 열에 라벨이 붙은 2D 테이블 객체, 즉 Excel 시트와 비슷하다.
import pandas as pd
# CSV 읽기
df = pd.read_csv('data.csv')
# 결측치 처리
df['age'] = df['age'].fillna(df['age'].median())
# 그룹별 통계
summary = df.groupby('sex')['age'].mean()
# 필터링
high_risk = df[(df['age'] > 65) & (df['stage'] >= 3)]ML에서의 위치 : 데이터 전처리 단계의 표준. ML 모델에 넣기 전에 Pandas로 정제하고 NumPy 배열로 변환하는 흐름.
df = pd.read_csv('data.csv') # Pandas로 읽고
df_clean = preprocess(df) # Pandas로 전처리하고
X = df_clean[features].values # NumPy 배열로 변환
y = df_clean['target'].values
model.fit(X, y) # ML 라이브러리에 전달의학연구 데이터는 거의 모두 표 형식이라 Pandas는 필수 도구이다. Pandas를 이용하여 데이터를 파이썬에 불러와 Numpy로 변환하여 ML 학습에 이용한다고 생각하면 된다.
2-3. Matplotlib (+ Seaborn) — 시각화의 표준
Matplotlib은 그래프와 시각화의 기반 라이브러리이다. 거의 모든 Python 시각화 도구가 이 위에 구축되어 있다.
import matplotlib.pyplot as plt
plt.plot(x, y)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()Seaborn은 Matplotlib 위에 더 예쁜 통계 그래프 인터페이스를 더한 라이브러리이다. 박스플롯, violin plot, heatmap 같은 통계 그래프는 Seaborn이 편하다.
2-4. SciPy — 과학 계산 보조
SciPy는 NumPy 위에 고급 과학 계산 기능을 추가한다. 통계 검정 (scipy.stats), 최적화, 희소 행렬 등. ML에서 직접 호출하는 일은 적지만 내부에서 자주 쓰인다.

3. ML/DL 라이브러리
이 단계가 가장 풍부하며, 각 세부 모델에 따른 라이브러리가 다르게 있을 수 있고, 대표적인 라이브러리만 소개한다.
3-1. scikit-learn — 전통적 ML의 표준
scikit-learn: machine learning in Python — scikit-learn 1.8.0 documentation
Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning. Algorithms: Grid search, cross validation, metrics, and more...
scikit-learn.org
scikit-learn은 전통적 ML 알고리즘의 표준 라이브러리이다. 의학연구의 80%는 이거 하나로 충분하다.
제공하는 것 :
- 거의 모든 전통적 ML 알고리즘 — 선형/로지스틱 회귀, SVM, k-NN, Decision Tree, Random Forest 등
- 데이터 전처리 — StandardScaler, OneHotEncoder, SimpleImputer
- 모델 평가 — accuracy, AUC, classification_report
- 하이퍼파라미터 튜닝 — GridSearchCV
- 파이프라인 — 전처리+모델을 한 객체로 묶음
가장 큰 강점 : 일관된 API. 모든 모델이 fit(), predict(), score() 같은 동일한 인터페이스를 가진다. 모델을 바꾸기 매우 쉽다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
# 어떤 모델이든 같은 방식
for Model in [RandomForestClassifier, SVC, LogisticRegression]:
model = Model()
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print(f'{Model.__name__}: {score:.3f}')
언제 쓰는가 : 정형 데이터의 전통적 ML 작업. 작거나 중간 크기의 데이터.
한계 : 딥러닝을 직접 지원하지 않는다. 신경망(MLPClassifier)이 있지만 매우 기본적인 수준이고, GPU 가속이 안 된다.
3-2. TensorFlow와 PyTorch — 딥러닝 양대 산맥
딥러닝(신경망) 작업은 scikit-learn으로는 안 되고 전용 프레임워크를 쓴다. 두 가지 표준이 있다.
TensorFlow : Google이 2015년 공개. 산업계의 프로덕션 배포에 강함.
PyTorch : Meta(Facebook)가 2016년 공개. 학계와 연구의 표준. 최신 AI 논문 코드의 90% 이상이 PyTorch이다. 의학연구에 있어서는 사실상 표준이다.
| TensorFlow | PyTorch | |
| 개발사 | Google (2015) | Meta (2016) |
| API 스타일 | Keras (선언적) | 명령형 (Python스러움) |
| 디버깅 | 어려움 | 쉬움 |
| 배포 | 강함 (모바일, 웹) | 개선 중 |
| 연구 점유율 | 감소 | 압도적 (학계 표준) |
| 학습 곡선 | 가파름 | 완만함 |
# PyTorch 예시 — 매우 명시적이고 Python스러움
import torch
import torch.nn as nn
class SimpleNN(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 64)
self.fc2 = nn.Linear(64, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
return torch.sigmoid(self.fc2(x))
model = SimpleNN()
Keras : TensorFlow의 고수준 API. 더 간결한 문법으로 신경망을 만든다.
# Keras 예시 — 매우 간결
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy')
model.fit(X_train, y_train, epochs=10)
4. 전형적 워크플로우 — 이 도구들을 어떻게 조합하는가?
실제 작업에서는 이 라이브러리들을 조합해서 쓴다. 전형적 흐름:
# 1단계: 데이터 로드 (Pandas)
import pandas as pd
df = pd.read_csv('data.csv')
# 2단계: 전처리 (Pandas + NumPy)
import numpy as np
df['age'].fillna(df['age'].median(), inplace=True)
X = df[['age', 'stage', 'tumor_size']].values
y = df['outcome'].values
# 3단계: 데이터 분할 (scikit-learn)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 4단계: 전처리 (scikit-learn)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_s = scaler.fit_transform(X_train)
X_test_s = scaler.transform(X_test)
# 5단계: 모델 학습 (XGBoost + scikit-learn 호환)
import xgboost as xgb
model = xgb.XGBClassifier(n_estimators=500)
model.fit(X_train_s, y_train)
# 6단계: 평가 (scikit-learn)
from sklearn.metrics import roc_auc_score
y_proba = model.predict_proba(X_test_s)[:, 1]
print(f'AUC: {roc_auc_score(y_test, y_proba):.3f}')
'의학 연구' 카테고리의 다른 글
| [비전공자의 머신러닝 의학연구 #4] 결정트리 Decision Tree (0) | 2026.05.02 |
|---|---|
| [비전공자의 머신러닝 의학연구 #3] 머신러닝 학습에 알아야할 개념들 (0) | 2026.05.02 |
| [비전공자의 머신러닝 의학연구 #1] 머신러닝의 개요, 분류 (0) | 2026.04.28 |
| 정부가 숨기고 있는 의대증원의 근거 (OECD 통계) (3) | 2024.02.18 |
| 역학연구에서의 인과성 - Bradford Hill criteria (0) | 2023.09.27 |


