이전파트에서 트리기반 모델 중 Bagging 계열 인 랜덤포레스트를 다뤘다면, 이번엔 앙상블의 다른 큰 줄기, Boosting 이다. 랜덤포레스트가 분산을 줄이는 방식 이었다면, 부스팅은 편향을 줄이는 방식이다. 특히 부스팅은 여러 머신러닝 대회에서 예측 정확도 1등 을 차지하는 경우가 많은 강력한 모델군이다.
1. 부스팅이란?
부스팅은 약한 모델 여러 개를 순차적으로 학습 하면서 이전 모델의 오차를 다음 모델이 교정 해나가는 앙상블 기법이다. 여기서 약한 모델 (weak learner) 이란 단독으로는 정확도가 낮은 모델 — 보통 얕은 결정트리 (depth 3~6) 를 사용한다. 이런 약한 모델들도 순차적으로 결합 하면 강력해진다는 것이 부스팅의 핵심 발상이다.

- 트리 1 학습 : 실제 정답을 예측. 일부는 맞고 일부는 틀린다.
- 잔차(오차) 계산 : 잔차 = 정답 − 예측. 어디에서 얼마만큼 틀렸는지 파악.
- 트리 2가 잔차를 학습 : 정답이 아니라 트리 1이 틀린 양 을 새 타겟으로 학습.
- 결합 : 최종 예측 = 트리 1 예측 + (η × 트리 2 잔차 예측). 정답에 더 가까워진다.
이 과정을 100~1000번 반복 한다. 각 트리는 이전까지의 잔차를 줄이는 데 집중하고, 결과는 모든 트리의 가중 합이 된다. 학습률 η 는 각 트리의 기여도를 조절하는 값이다 (보통 0.01~0.3).
잔차만 추가 학습하는데 왜 정답에 가까워지나?
정답 = 예측 + 잔차 ← 잔차의 정의
정답 = 예측 + (잔차의 예측) ← 잔차도 예측 가능하다면
만약 잔차를 완벽하게 예측 할 수 있다면 — 첫 예측에 그 잔차 예측을 더하기만 해도 정답이 된다. 잔차도 완벽히는 못 맞히지만 방향만 맞아도 정답에 가까워진다.
환자 한 명의 실제 종양 크기 = 20 mm 라고 하자.
| 라운드 | 누적 예측 | 잔차 | 새 트리 예측 | 새 누적 예측 |
| 1 | 14 | 6 | — | 14 |
| 2 | 14 | 6 | 4 | 18 |
| 3 | 18 | 2 | 1.5 | 19.5 |
| 4 | 19.5 | 0.5 | 0.3 | 19.8 |
| 5 | 19.8 | 0.2 | 0.15 | 19.95 |
잔차가 6 → 2 → 0.5 → 0.2 → ... 로 점점 작아지면서 누적 예측이 정답 20 에 수렴한다.
왜 잔차가 점점 작아지는가?
이유 1 — 잔차에는 패턴이 남아있다
트리 1이 모든 패턴을 다 잡지 못해서 잔차가 발생한다. 그 잔차에는 트리 1이 놓친 패턴 이 들어있다 — 예를 들어 트리 1이 나이만 보고 예측했다면, 잔차에는 병기·종양크기 등의 영향 이 남아있다. 트리 2가 그 패턴을 학습한다.
이유 2 — 학습률이 보호 장치
만약 트리 2의 잔차 예측이 틀렸다면? 학습률 η = 0.1 이면 트리 2의 기여는 잔차 예측의 10%만 반영된다. 틀려도 큰 손해 없이 조금씩 보정 한다. 이게 부스팅이 안정적으로 수렴 하는 비결이다.
무한히 더하면 정답에 도달하나?
아니다.
- 과적합 — 훈련 데이터 잔차는 0에 수렴하지만, 테스트 데이터의 오차는 어느 시점부터 다시 커진다
- 수렴 속도 — 학습률 때문에 잔차가 기하급수적으로 줄어드나 완전히 0이 되진 않음
그래서 적절한 라운드에서 멈추는 것 (Early Stopping) 이 핵심이다.
같은 트리, 다른 타겟
오차를 어떻게 트리로 학습하지? 답은 단순하다. 같은 결정트리 알고리즘이지만, 매번 학습 타겟이 바뀐다.
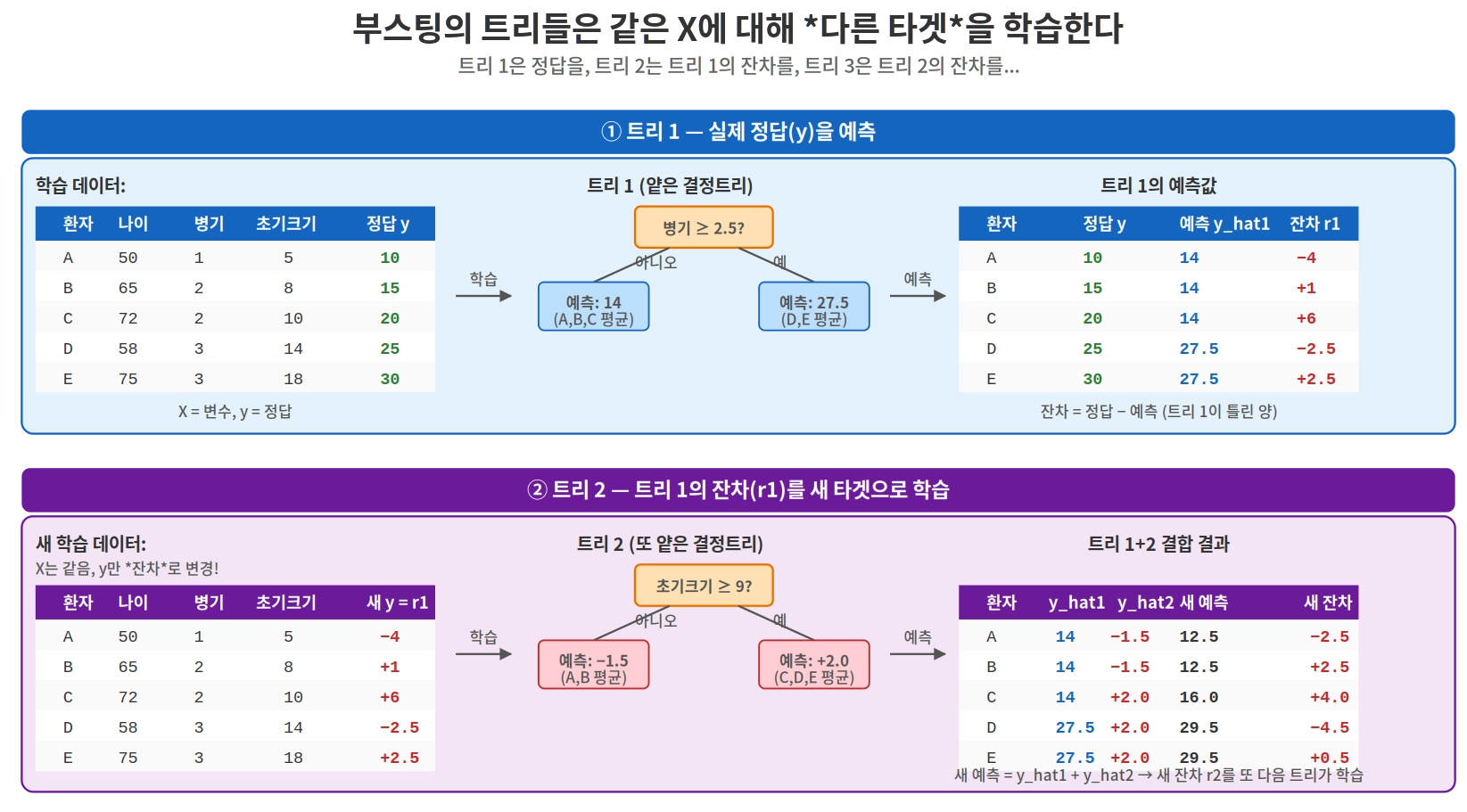
| 입력 (X) | 타겟 (y) | 알고리즘 | |
| 트리 1 | 환자 변수 | 실제 정답 (10, 15, 20, 25, 30) | 결정트리 |
| 트리 2 | 환자 변수 (똑같음!) | 트리 1의 잔차 | 결정트리 (똑같음!) |
| 트리 3 | 환자 변수 (똑같음!) | 트리 2 후의 새 잔차 | 결정트리 (똑같음!) |
X와 알고리즘은 같지만, 매번 타겟이 바뀐다. 결정트리는 어떤 숫자든 평균낼 수 있어서, 정답이든 잔차든 같은 알고리즘으로 학습 가능하다.
라운드별 수렴 과정

- 라운드 1 — 예측이 정답에서 많이 떨어짐 (큰 잔차)
- 라운드 5 — 누적 효과로 거의 일치
- 라운드 50 — 예측이 정답과 완전히 겹침
학습 곡선이 보여주듯 라운드가 늘수록 손실이 지수적으로 감소 한다. 어느 시점부터는 평탄한 구간 이 오는데 — 이때부터 과적합 이 시작될 수 있다.
2. Gradient — 부스팅의 진짜 메커니즘
위에서 "잔차" 라고 단순화했지만, 일반적으로는 gradient 가 그 자리를 차지한다. Gradient 란 함수가 가장 빠르게 증가하는 방향과 속도로 1차원에서는 기울기, 다차원에서는 각 변수에 대한 편미분의 벡터, 머신러닝에서는 손실을 줄이려면 반대 방향으로 가야 할 신호, 부스팅에서는 "무엇을 어떻게 보정해야 하는가" 의 정확한 신호이다.
이름이 "기울기" 보다 "gradient" 로 굳어진 이유는 다차원 벡터 라는 점을 강조하고 싶어서이다. 한 변수만 있으면 slope, 여러 변수가 있으면 gradient. 둘 다 "어디로 가야 함수가 더 커지는가" 의 같은 정보를 준다.
Gradient Boosting은 손실 함수의 gradient를 다음 모델이 학습 하는 방식으로 경사하강법을 모델 공간에 적용 한 부스팅 기법이다.
이름 그대로 Gradient (기울기를 따라) + Boosting (순차적으로 모델을 추가) 의 결합이다.

Friedman (2001) 의 논문은 부스팅을 완전히 새 관점에서 봤다.
- 기존 부스팅의 직관 : "잔차를 다음 트리가 학습한다"
- Friedman의 재해석 : "손실 함수의 음의 gradient를 다음 트리가 학습한다"
이 두 표현이 MSE 손실에서는 정확히 같다. 하지만 gradient 표현 이 훨씬 일반적이며 어떤 손실 함수에도 적용 가능 하다.
3. XGBoost — 부스팅의 표준
XGBoost (eXtreme Gradient Boosting) 란 부스팅알고리즘의 대표적인 구현체로 Tianqi Chen 2016 의 논문에서 제안된 후, Kaggle 대회 우승의 단골 이 되며 부스팅을 대중화시킨 표준 구현체이다.
XGBoost는 Friedman의 GBM 프레임워크 를 기반으로 핵심 개선을 추가한 것이다.
- 2차 미분(Hessian) 활용 — 기울기뿐 아니라 곡률 정보 까지 사용해 한 라운드에서 더 큰 개선
- L1·L2 정규화 — 트리의 복잡도에 페널티를 줘서 과적합 방지
- 결측치 자동 처리 — NaN을 자체적으로 다룸 (전처리 부담 ↓)
- 병렬 처리 — 트리 내 노드 분할은 병렬화 가능
- Early Stopping — 검증 점수가 안 좋아지면 자동 중단
이름의 X — eXtreme 은 두 가지를 의미한다.
극도로 효율적 : 기존 GBM 대비 수십 배 빠른 학습 속도. 이게 Kaggle 대회에서 우승하기 시작한 이유 — 같은 시간에 더 많은 실험 을 할 수 있었다.
극도로 정확 : Hessian + 정규화의 조합으로 기존 GBM보다 더 정확. 같은 데이터에 대해 더 좋은 일반화 성능. 속도와 정확도를 동시에 극단까지 밀어붙였다 는 의미.
핵심 하이퍼파라미터
| 파라미터 | 의미 | 권장값 |
| n_estimators | 트리 개수 | 100~1000 (Early Stopping과 함께) |
| learning_rate | 학습률 η | 0.01~0.3 |
| max_depth | 트리 최대 깊이 | 3~6 (얕게!) |
| subsample | 행 샘플링 비율 | 0.7~1.0 |
| colsample_bytree | 열 샘플링 비율 | 0.7~1.0 |
| reg_alpha / reg_lambda | L1 / L2 정규화 | 0~1 |
| early_stopping_rounds | 조기 종료 | 10~50 |
입력 데이터 형식 — DMatrix vs sklearn API
XGBoost는 두 가지 인터페이스 를 제공한다. (둘 다 표준이다.)
# 옵션 1: scikit-learn API (DataFrame/NumPy 그대로)
model = xgb.XGBClassifier(...)
model.fit(X_train, y_train)
# 옵션 2: Native API (DMatrix 사용)
dtrain = xgb.DMatrix(X_train, label=y_train)
model = xgb.train(params, dtrain, num_boost_round=300)
의학연구 분석에서는 sklearn API 가 일반적으로 권장된다 — Pipeline, GridSearchCV, SHAP 등 sklearn 생태계와의 호환성 때문이다. 하지만 Native API 형태도 동일한 결과를 출력한다.
파이썬 코드
패키지 설치 : pip install xgboost
import xgboost as xgb
model = xgb.XGBClassifier(
n_estimators=1000,
learning_rate=0.05,
max_depth=5,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha=0.1,
reg_lambda=1.0,
eval_metric='auc',
early_stopping_rounds=50, # 50라운드 동안 안 좋아지면 중단
random_state=42,
n_jobs=-1
)
model.fit(
X_train, y_train,
eval_set=[(X_val, y_val)],
verbose=False
)
생존분석 — XGBoost survival:cox
XGBoost는 Cox 손실 함수 를 직접 지원하면서 생존분석으로의 확장이 가능하다.
model = xgb.XGBRegressor(
objective='survival:cox',
eval_metric='cox-nloglik',
n_estimators=300,
learning_rate=0.05,
max_depth=3,
early_stopping_rounds=30,
random_state=42
)
# Cox 라벨 인코딩: event=1 → +time, event=0 → -time
label = np.where(y_event == 1, y_time, -y_time)
model.fit(X_train, label_train, eval_set=[(X_test, label_test)])
# 위험 점수 예측
risk = model.predict(X_test)
Cox PH 가정 없이 비선형·상호작용을 자동 학습하면서, 부스팅의 높은 정확도 를 가져갈 수 있다. 생존분석을 위하여 절단값일때 시간(time)을 음수로 코딩하여 구분한다.
4. 다른 부스팅 라이브러리
XGBoost 외에 자주 쓰이는 두 라이브러리는 LightGBM과 CatBoost이다.
- LightGBM (2017, Microsoft) — 속도가 가장 빠름. 대용량 데이터(수백만 행)에 강함. Leaf-wise 성장 방식. 작은 데이터에선 과적합 위험.
- CatBoost (2017, Yandex) — 범주형 변수 자동 처리 가 핵심. one-hot 인코딩 없이 그대로 입력 가능. 의학 데이터의 Stage, Sex, Grade 처럼 범주형 범주가 많을수록 강점.
모두 같은 Gradient Boosting 프레임워크 의 구현체이고, 기본 작동 원리는 동일하다. 코드 패턴도 비슷해서 한 번 익히면 쉽게 옮겨갈 수 있다.
'의학 연구' 카테고리의 다른 글
| [비전공자의 머신러닝 의학연구 #8] DeepSurv — Cox 회귀 + 신경망 (1) | 2026.05.10 |
|---|---|
| [비전공자의 머신러닝 의학연구 #7] 딥러닝과 MLP (0) | 2026.05.08 |
| [비전공자의 머신러닝 의학연구 #5] Random Forest, Random Survival Forest (0) | 2026.05.03 |
| [비전공자의 머신러닝 의학연구 #4] 결정트리 Decision Tree (0) | 2026.05.02 |
| [비전공자의 머신러닝 의학연구 #3] 머신러닝 학습에 알아야할 개념들 (0) | 2026.05.02 |
